
Weed of the week NFT preparations
Weed of the week NFT preparations
Choosing an NFT marketplace and classifying listings by strain

Believe it or not, it is tough to find on-chain use cases for the price of weed. The original idea was to create a prediction market that uses the price in order to resolve, but Hedgehog isn’t open yet. In the meantime, Cluutch will instead create NFTs that are inspired by weed.
Weedies* will eventually be automatically generated cartoon weed buds. Think of a cross between the cute meaninglessness of Bored Ape, mixed with some structured information, à la Leafly.

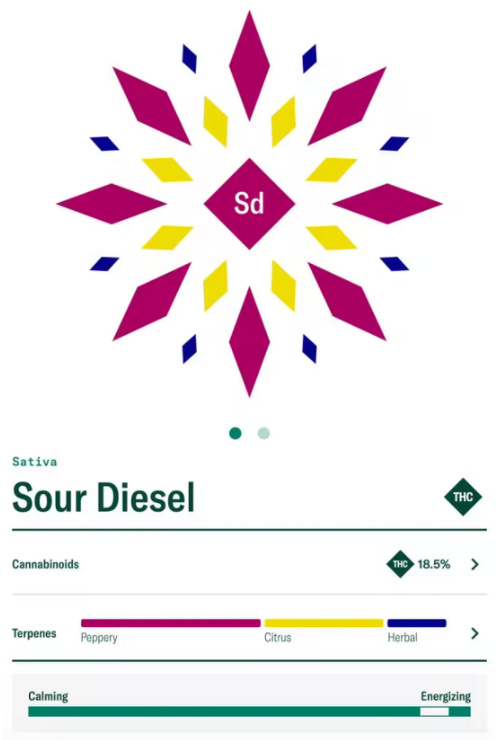
Automating the image generation will take some time, so the first proof of concept will be manual and less frequent. This blog post investigates some options for execution.
* “Weedies” is already taken. New name needed.
Weed persona
What's in a name? that which we call a rose
By any other name would smell as sweet;
The eventual goal is for updates to the Cluutch weed price API to trigger on-chain NFT creation. Each NFT should give some meaningful and entertaining representation of the API at that snapshot in time. Our API contains price information taken from dispensaries around the US, scraped daily.
The natural way to group these listings is by the strain of weed being sold. With names like Soulshine Narnia and Purple Stomper, weed strain names are full of personality and will serve as the best caricatures to capture in NFTs.
The problem is that, strain names are not recorded in structured fields on most dispensary websites. Instead, a generic title is used that typically contains a combination of the stain, quantity, merchant name, and form (hash, flower, shake, etc).
I tried creating a BigQuery ML multi-class model to classify the titles into different strains programatically, but it doesn’t support more than 50 labels. To move forward, I would need to create training data (maybe using mTurk again) where a subset of entries have the strain filled out by a human.

To get unblocked for now, I loosened the requirements. Instead of trying to classify entries into specific strains, the presence of keywords is used as a proxy.

This method has a lot of imperfections. Only the first keyword is selected, so words used in earlier parts of the switch statement will be overrepresented. Substring matching is being used so terms like “red” which are meant to match the color, will also be grouped with unrelated words like “kindred”. Despite these limitations, the results are still informative.

Given these results, the first Weedie NFT will be for the most expensivest weed right now, Moonbow. Any illustrators out there have an idea for a Moonbow nug that looks like the real thing but also has some extra flair?

Marketplace selection
The Solana NFT ecosystem has come along way since I last tried things out a few months ago. Holaplex and Burnt Finance are two no-code apps where you can create an NFT with just a few clicks.
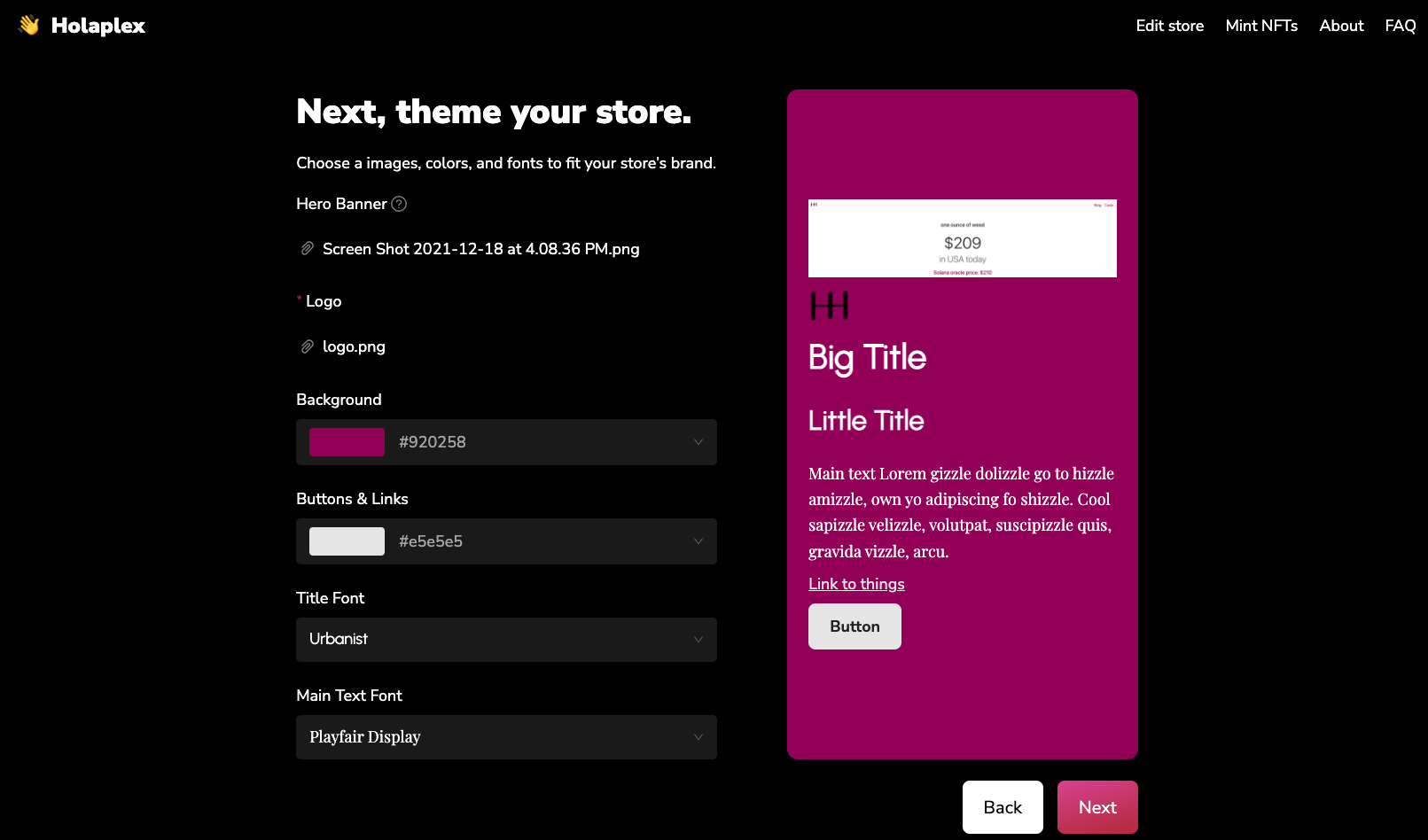
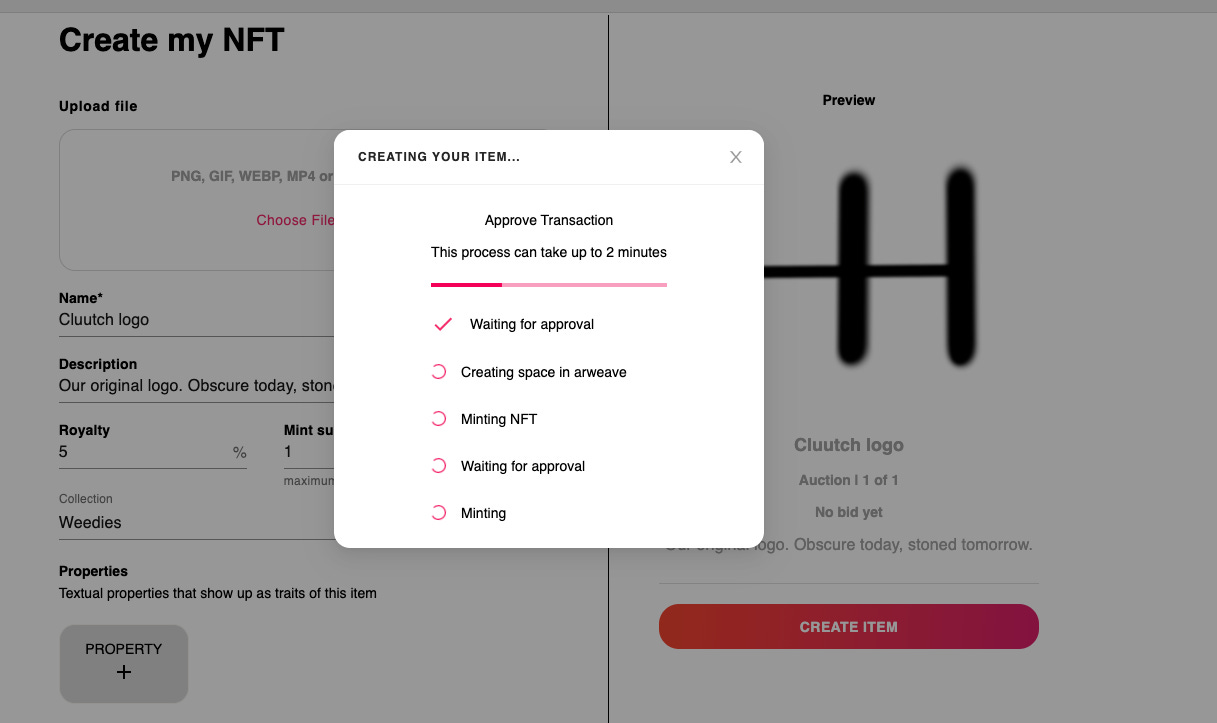
I’ll try out a different one for the first few weeks. The web UX will be important but I also want one that I can actually interact with on-chain (programatically mint new NFTs and fetch current auctions from cluutch.io).
API and oracle maintenance
Given this week turned out to be mostly a research week, now is a good time to give an update on some unsexy maintenance concerns. The first thing to note is that migrating to Cloud Functions from Dataprep has cut costs to about 1% of what they were before the switch. Dataprep had a flat $100 / month fee plus usage fees for the components it spun up. It had to be run manually, so costs varied by month but averaged around $120.
With Cloud Functions, it is basically free to achieve the same things as before, but with automatic updates. Compute Engine is the only real cost now, but that is related to the Switchboard oracle and would be required even if Dataprep was still being used for data ingestion.

I am also keeping an eye on Switchboard’s migration to v2. v2 is only available on devnet now and it looks nice but still isn’t ready for primetime. Bundle creation is working but feed creation fails at the last step.

Arweave mining update
Last week, I setup a basic Arweave miner. It’s running on an off-brand (cheap) VPS with only 500 GB HDD. I was expecting some minimal mining earnings, but exactly zero mining has been completed so far. On the other hand, I was expecting the server to just fall over because miner would use up all the storage given no explicit limits were set. But 20 GB is staying free and the miner remains responsive.
# df -h
Filesystem Size Used Avail Use% Mounted on
udev 7.8G 0 7.8G 0% /dev
tmpfs 1.6G 528K 1.6G 1% /run
/dev/xvda1 500G 481G 20G 97% /
I’ll probably iterate on this over the next few weeks. I’ll buy a large HDD and NVMe drive in order to compare results.