
Migrating the Cluutch API from Rails and mTurk to Google Cloud for serverless API and data ingestion
Moving from a Rails API server hosted on Heroku to Google Cloud Functions. Also from a weed price aggregation pipeline built with mTurk to using paid web scrapers and Cloud Data Fusion.

Otreeba seems to have a good API for weed metadata. You can use it to get high level information about different strains, products, and more.
But price information is missing from this picture. Price of Weed and Leafed Out do have price information but it’s not as easy to consume. The goal of this blog is to:
Build an API for the price of weed
Expose that API within Solana
Consume the on-chain data by a Solana program
#1 was implemented back in March as a Rails API and #2 has been solved two different ways. First, a custom oracle was written as part of the Solana hackathon that polled api.cluutch.io and copied the results onto Solana. More recently, we replaced the custom oracle with a mature solution from Switchboard.
This blog post reevaluates the implementation originally chosen to implement #1 and presents a new solution.
Reevaluation of current pipeline
When I started this blog as a new years resolution, the requirements were different. At the time, I wanted:
A low cost solution: Now that I’ve invested so much time into this project, I’m willing to spend $100 - $300 / month, whereas I originally limited spend to no more than $100 / month.
Complex price parsing rules: The price of weed is currently defined as the lowest price for a flower of weed. There are a lot of details to consider when a human is responsible.

Cluutch mTurk submission rules Use the websites that are most popular in each state: Although some websites like Weed Maps are gaining traction, there is no national standard for where people go to shop for weed. The new strategy will be to focus on two of the most popular websites, Weed Maps and Where’s Weed, instead of trying to support all sites.

Given the original requirements above, the current Cluutch weed price collection pipeline involves a lot of humans. Although I planned to run the pipeline 3 times a week, in reality it gets run about once a month because the process is so time consuming.
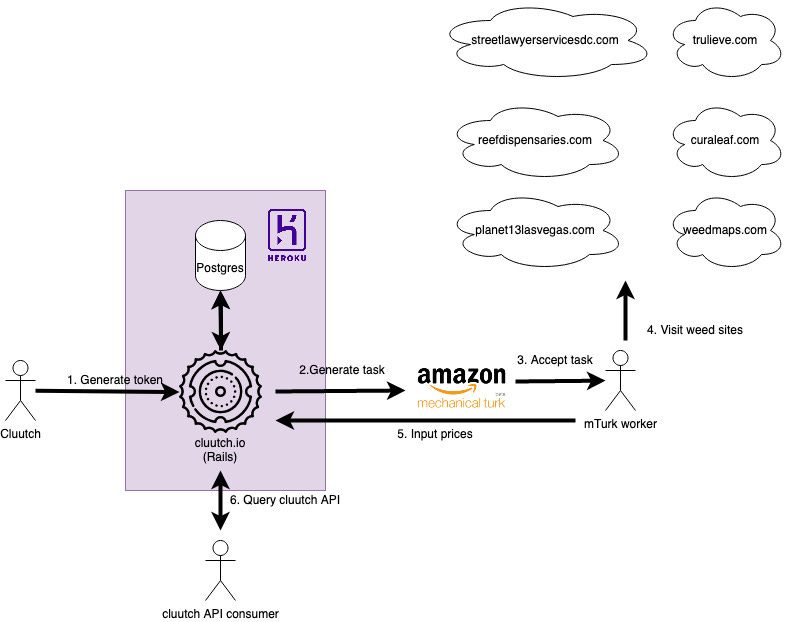
Generate token: Pregenerated tokens are used to make the website publicly accessible to mTurk workers. I have to personally click around the site to generate these tokens and save them to CSV.
Generate task: Each mTurk task is a form with 9 prices for the worker to input. The token from #1 is uploaded and becomes part of the link the worker clicks on.
Accept task: The task is listed in the mTurk marketplace and any worker can accept it.
Visit weed sites: The worker must visit all of the predefined webpages and search for the cheapest price of weed on each site.
Input prices: The worker then completes the price input form on cluutch.io.
Query cluutch API: The Cluutch price collection form and public API are part of the same Rails app.
This process is expensive, not scalable, requires a lot of humans, and there is a lot of code considering the lack of complexity of the flow. Money may not solve all of life’s problem’s but it will make Cluutch’s job easier in this case. By paying a 3rd party data scraper to collect weed prices, I can focus on exposing the results they provide through a serverless API.
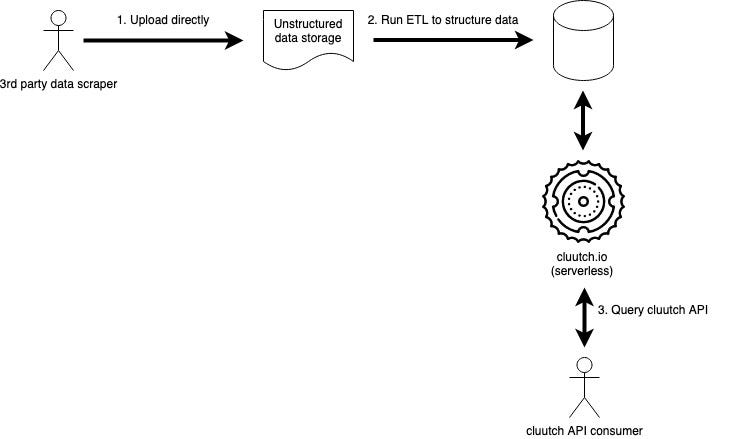
I’m waiting on more quotes from possible scrapers. Next week’s post will go into more detail about the selection process. The rest of this post assumes somebody will upload a data dump somewhere and sets up a pipeline to persist that dump into a structured store and then expose the data via a serverless solution.
ETL with Google Data Fusion
I have a good amount of experience with AWS. For the sole reason of trying something new, Google Cloud is being used. Google Data Fusion (GDF) provides a user friendly interface to define an ETL.
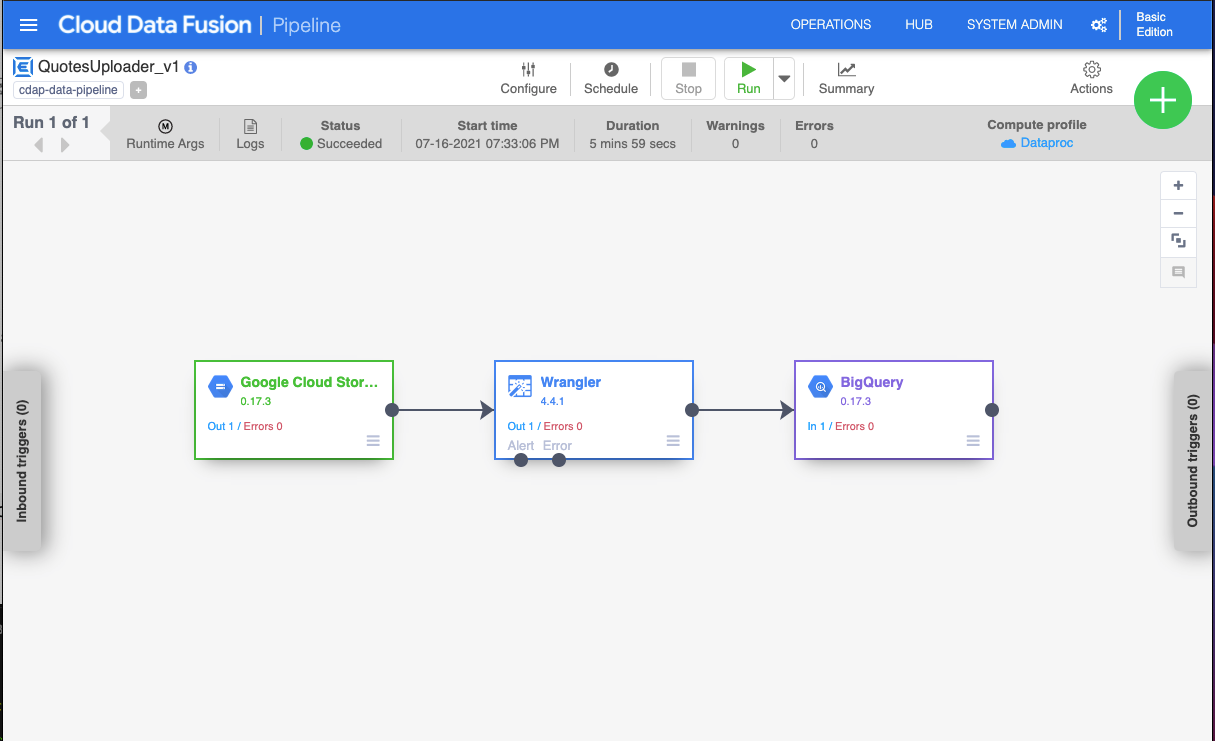
Setup Google Cloud Storage
Google Cloud Storage (GCS) is Google’s equivalent of S3. I created a project where the data scrapers can upload their dumps. I then added a corresponding source node on GCF referencing the GCS path.
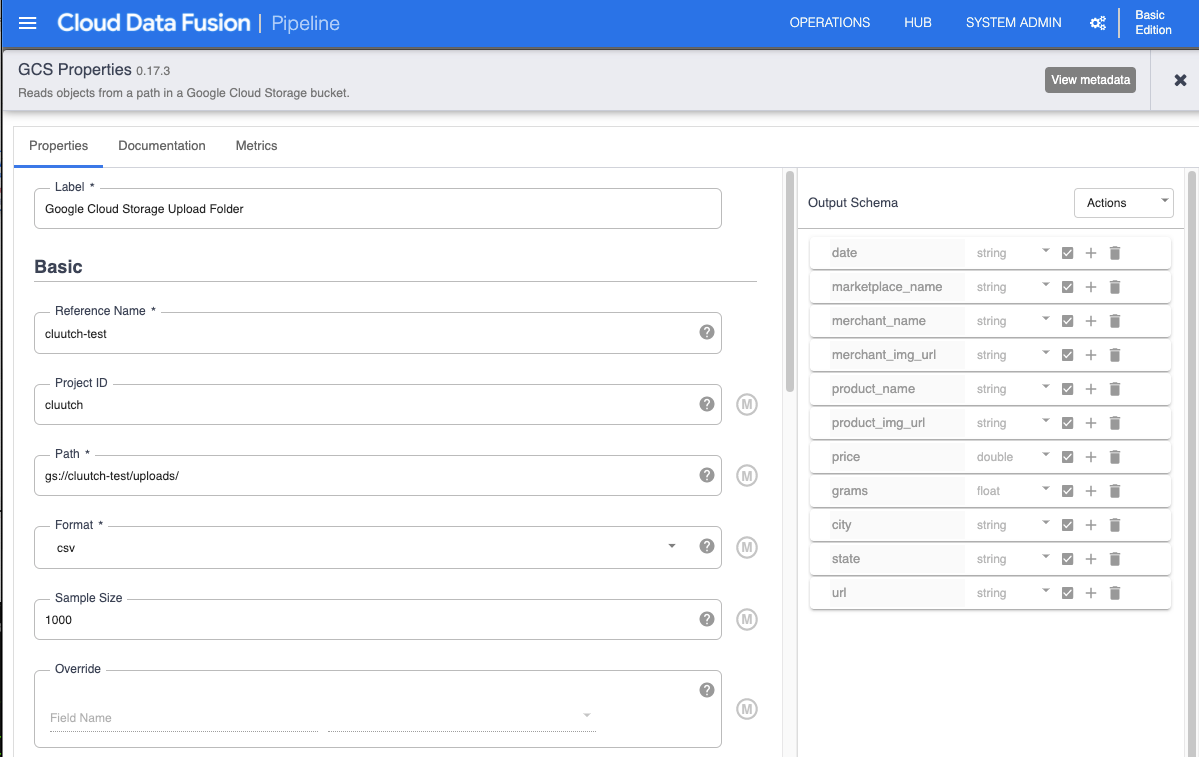
Parse date with Wrangler
For whatever reason, the way dates are formatted are never how your program is expecting. This Wrangler node converts the date from a String to a Date.
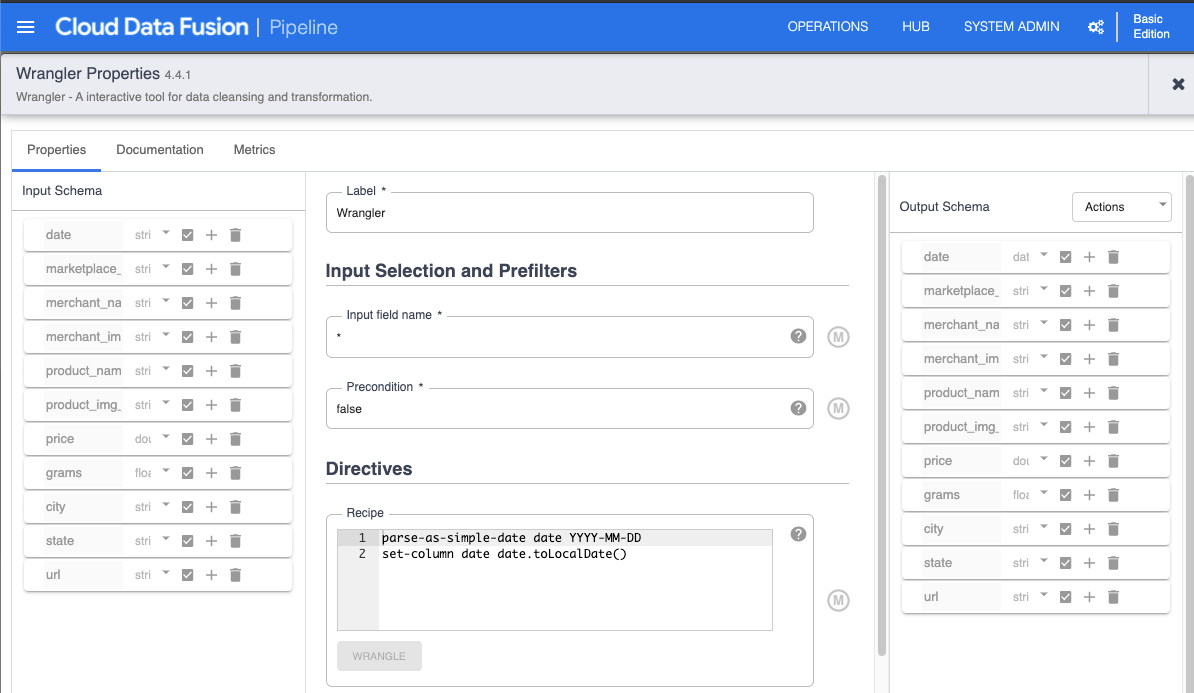
Write result to BigQuery
Google Cloud Functions (GCF) will be used for serving the API. It will query the results from BigQuery.
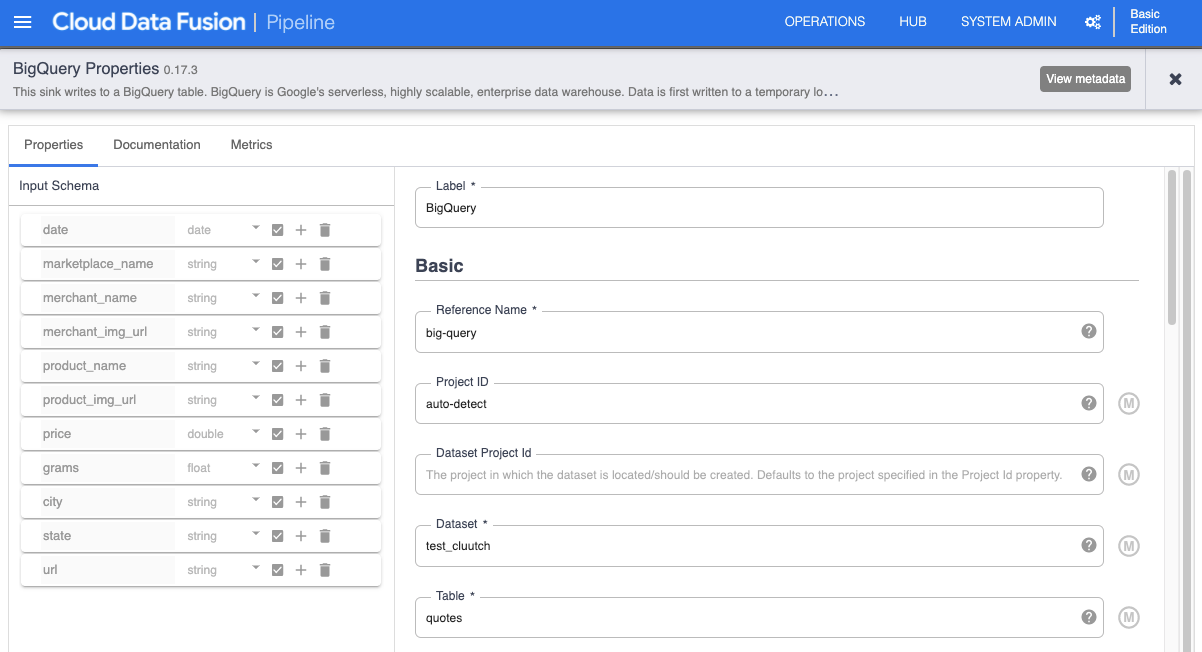
Serverless API with Cloud Functions and BigQuery
Although I’m using a test CSV with a single entry in it, we can imagine it actually contains thousands of rows, provided by a 3rd party web scraper. The final challenge is exposing this data, now stored in BigQuery, over an HTTP API.
To do this, I wrote a GCF that queries the BigQuery dataset.
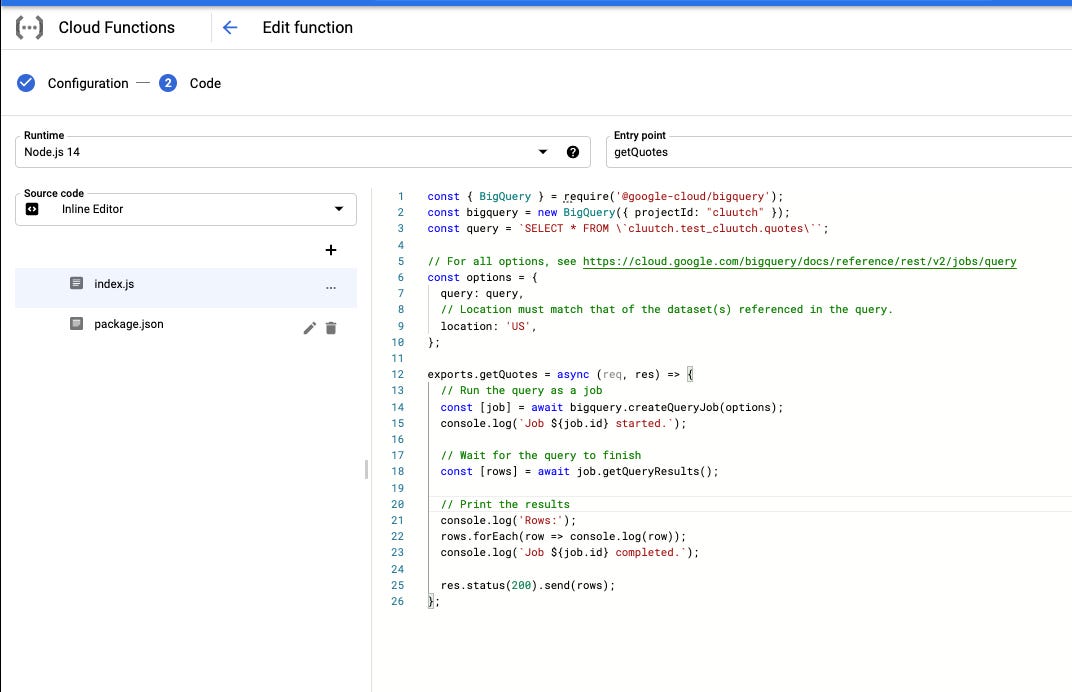
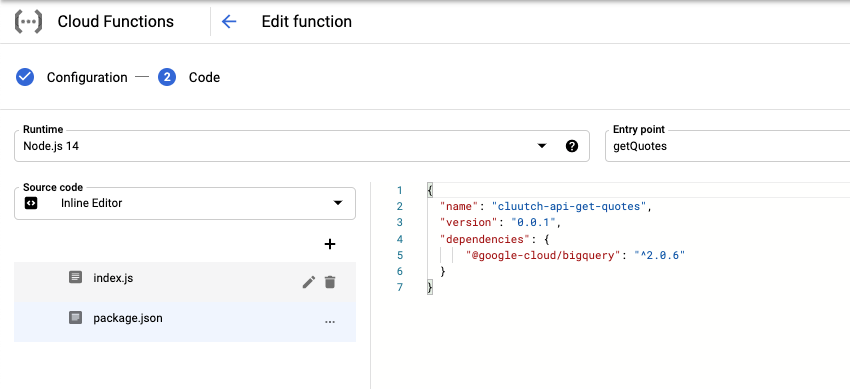
In order to make the function publicly accessible, it’s permissions had to be tweaked.
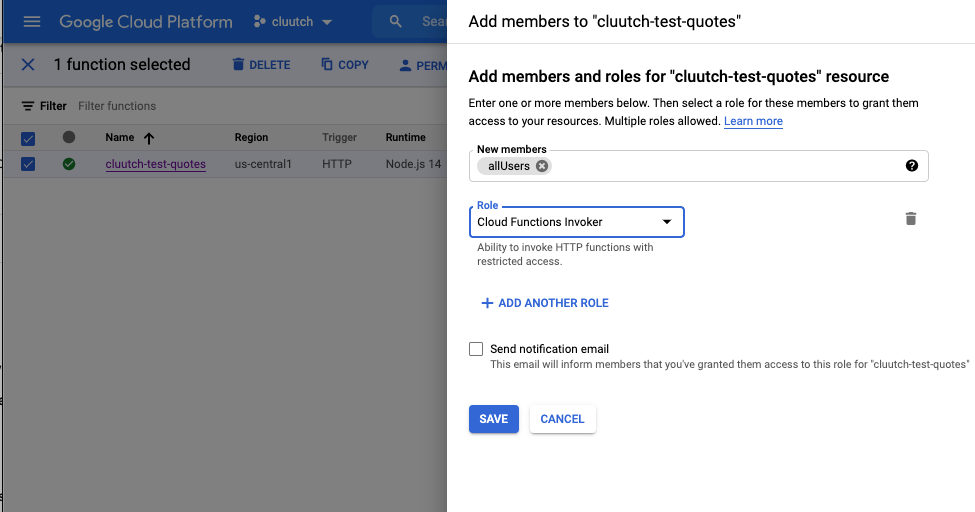
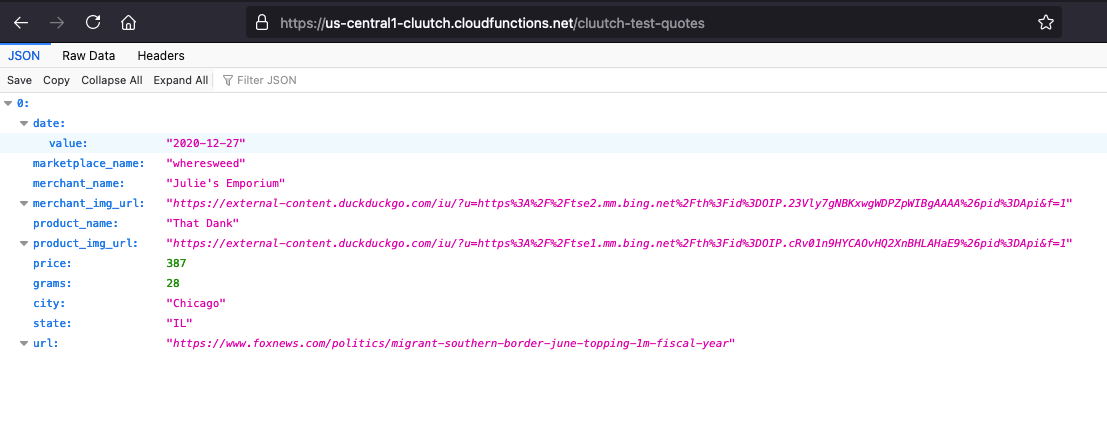
With all of that done, the API can now be accessed: https://us-central1-cluutch.cloudfunctions.net/cluutch-test-quotes
Future work
Despite the progress, this is all just a proof of concept. The current cluutch API still points to the old Rails stack. These are the steps I’ll need to take to make it production ready.
Select a scraping vendor. Determine final list of fields to scrape.
Recreate pipeline using production naming conventions.
Add a BigQuery view that calculates daily averages. Expose it from a new GCF.
Update DNS so api.cluuch.io resolves to new pipeline.
Update cluutch.io accordingly, migrate to professional CMS like Webflow.