
Building a Crypto Weed App: Part 7 - To mTurk, or not to mTurk
Why I decided not to crowdsource and use mTurk to collect daily weed prices (yet).

Recap
This blog documents my journey learning about crypto and new tech through a real world project. Get caught up:
Part 1 - Working Anonymously (first paid post, WIP)
Part 2 - Barebones API: Set up a bare bones Rails server
Part 3 - Going Live: Deploy site to Herkou
Part 4 - Pretty Things: Make site look good and SEO optimized
Part 5 - But really how much: Prices organized by location
Part 6 - Is Augur the Best Oracle for cluutch: Review of oracle technology
Automating weed price collection
This week, I was hoping to continue exploring Augur as a viable platform for a cluutch oracle MVP. But I’m struggling to keep up with the daily price input. I have faithfully collected prices on 8 of the 11 days (73%) since I started keeping track.
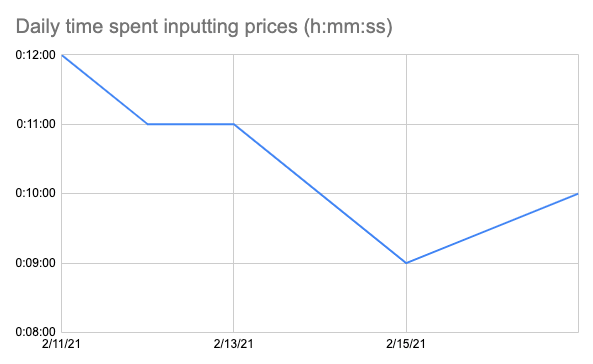
On average it takes me 10m36s to input the 12 prices (4 locations, 3 prices taken from each). That’s about 53s per price. This is higher than the 45s I originally estimated the task would take. Adding 11min of boring data collection everyday in on top of new content generation is asking a lot. Its time to start automating the collection of weed prices.
Considering the options
Over the past few weeks, I have been experimenting with Fiverr, TaskRabbit, and mTurk. I arbitrarily picked these tools because I had already heard of them. I also stumbled on, and poked at, Tartle but didn’t go nearly as deep.
Fiverr
Fiverr was the first app I tried out. Jobs on Fiverr are called Requests and the form to create them is very basic.
I made a listing titled “Marijuana price data collection”. I had some back and forth with people who expressed interest. I asked them about their familiarity with weed and with Tor. Nobody I talked to would admit to ever having used either.
On Fiverr you can also browse Services. I found it hard to evaluate who would be a good fit. At that time, the cluutch process for determining weed prices was to compare “similar hybrid strains”. Now I just take the cheapest from each website. That said, a lack of familiarity with weed was problematic.
Fiverr’s pricing model also isn’t great for what I need. I’m sure I can negotiate to pay per row of data entered but Fiverr seems like it is meant to be used on more of a project basis.
Task Rabbit
On Task Rabbit, tasks are based on geographic location. That makes it awkward to use when you are trying to be incognito. Its also an unnecessary way find collaborators given everything can be done virtually. Maybe I’m missing something but has Task Rabbit not heard of COVID and work from home?
After picking an arbitrary location and trying it out anyways, I found that the pricing model is a little better than Fiverr’s. Taskers charge by the hour and I assume that time could be broken up throughout the week. Even within the same city, there is a big range of $20 - $90 / hour where the system recommends taskers.
So long as its possible to spoof my location and pick a tasker working anywhere, this could be a viable option. It probably would not be a great long term solution because it doesn’t scale.
I Heart Mary Jane has a pretty extensive list of dispensaries, totalling 1,380 stores. If cluutch wanted to collect 3 prices from each store, it would take 42h of data entry according to current rates. Thinking about hiring 8 different taskers per day to do 5h of data entry each through Task Rabbit sounds like an awful idea.
Granted, there’s no need to operate at that scale yet, but its a good benchmark to keep in mind.
mTurk
I hate to say it, but Amazon has the best tool for the job. The other tools are generalized to tasks. mTurk is specific to and focuses on data generation and classification.
On mTurk, jobs are called HITs or “human intelligence tasks”. Last week I created an mTurk project to collect weed prices.
The form that actually gets filled out has the same information as I am inputting into cluutch myself: website name, store name (in case website is a marketplace), and price for the cheapest ounce. Some fields like date, url, jurisdiction, and isPrimary can be inferred from the rest of the information or are provided by Amazon. I added productImageUrl to try to better understand which item was used for determining price.
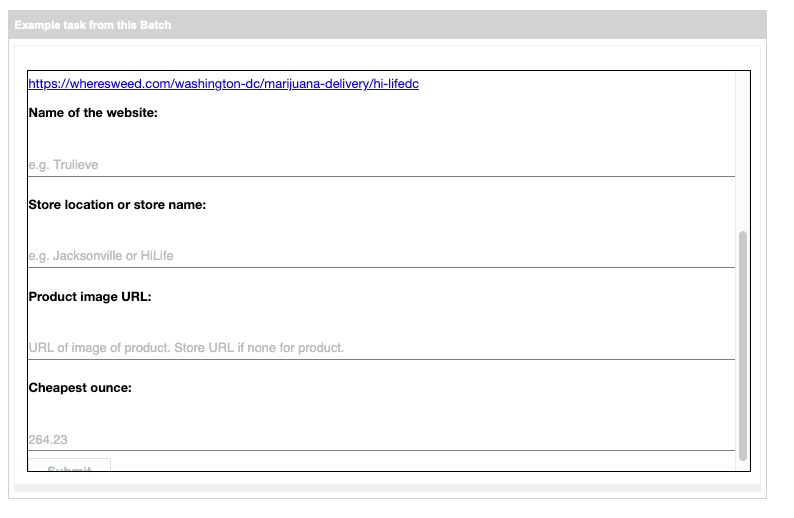
But even though the form is straightforward, the task is not. Taking into account your average person’s lack of knowledge about weed and the inconsistent layout of the websites, it is important to be very explicit about the rules. These are the instructions from the mTurk listing.
Instructions: Click the link below to review the Website. Find the cheapest ounce of weed and enter the price. Follow these rules for knowing which price to use:
Only consider "flower". Do not consider edibles, concentrates, hash, or any form of weed other than the bud.
An ounce is 28g. Always use the prices for product closest in weight to an ounce without going over. If ounce prices are available, use those.
If there are no prices for exactly an ounce, use multiples of the largest quantity available, without going over. For example, if 1/2 oz. (14g) is selling for $100 cheapest, then the cheapest price for an ounce is $200.
Do not use prices if they are for more than an ounce. If 2 oz. (56g) are available, do not use their prices. Use the closest quantity for sale less than or equal to an ounce.
Only consider products that contain some THC. CBD or other types of flower are not to be counted.
Sativa vs indica is not relevant. Neither are growing conditions, THC concentration, or other attributes. As long as the price is for THC containing flower, it can be included.
At the time of this writing, the project has been running for 5 days. It has collected 23 of the 35 quotes requested. The project is setup to pay out 40 cents per HIT and costs $13.50 in total to run. Here’s the full breakdown:

Even though I failed to get enough responses to be useful, there were still many lessons learned to help inform future work:
Any unexpected behavior from a weed website is likely to confuse turkers. When possible, the link provided is pre-filtered to an ounce of flower. In at least one case, a full ounce was no longer available, so that page said “out of stock”. Many HITs recorded -1 or “out of stock” even though there were 1/2oz options that could have been used for pricing.
Getting results one quote at a time is annoying as hell. Every day requires 12 quotes. Because results with mTurk are less reliable than doing myself, I am requesting each quote have 3 HITs for it and average the results. This means that every day, I now have to validate at least 36 different data points, instead of just generating 12 points myself.
Data quality is obviously problematic. Even with this small sample size, there is a lot of variance in how people input basic fields like “store name”.
mTurkers know how to get image URLs. If you right click on an image, you can copy the URL to the source file. There were no issues collecting this information. But it was not helpful.
It takes other people longer to collect prices than it does me. It takes me 45s on average to complete each weed quote. It takes turkers an average of 2m6s. This is the distribution.
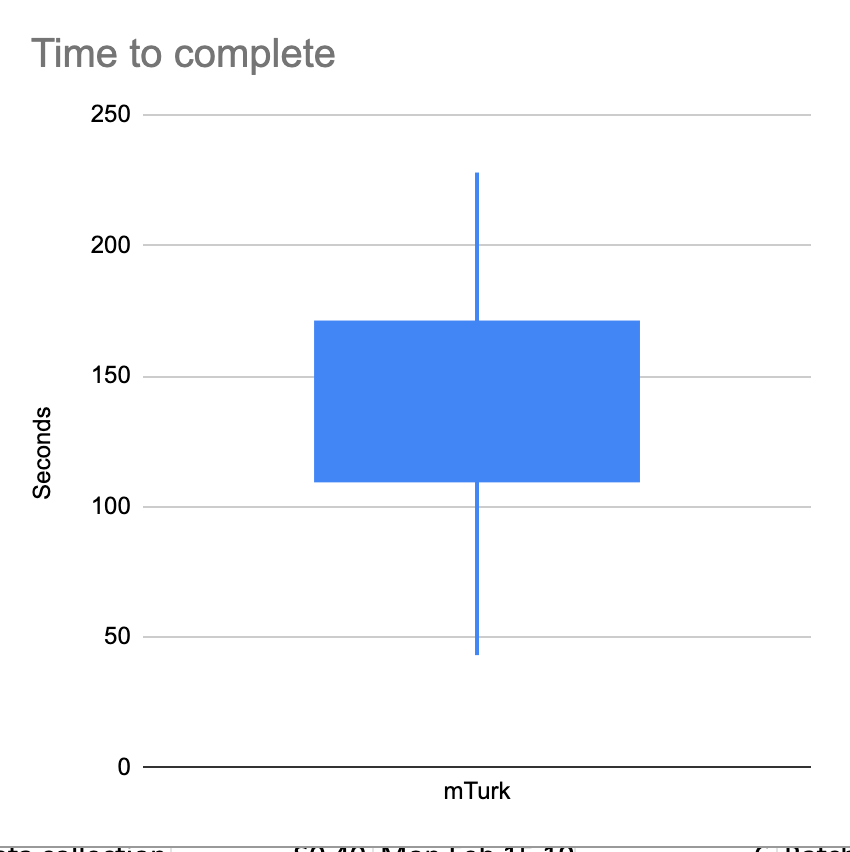
A new strategy for data collection
Moving forward, cluutch will only collect weed prices 3 times a week. I will personally continue to collect prices from Tor/Cannahome. mTurk will be used to collect prices from Nevada, Florida, and California. I will continue to collect 3 quotes per location. This is equivalent to 9 quotes from mTurk per day.
Pricing
Instead of paying per quote, I will pay a larger amount for the completion of all 9 quotes. Assuming the task continues to take 2m6s per quote and paying $15/h (or 53 cents/quote), this is how much it will cost:
Num locations * quotes per location * price per quote
3 * 3 * $0.525 = $4.725 per submission
Hopefully $4.725 will be attractive enough to turkers to participate. And it also more accurately reflects the amount of time they will spend on it.
Finally, for data quality, 2 different submissions for each quote will be required per day. This brings the monthly cost to:
Price per submission * num duplicates * num per week * weeks per month
4.725 * 2 * 3 * 4 = $113.4
This is right around the target butget of $100 / month for data collection.
Data pipeline
I can already feel this process starting to snowball out of control. It only takes 10min per day for me to record all prices. I’ve probably spent 10 hours since this project started investigating ways to automate it. Even if the plan above works, I’d still have to worry about getting mTurk results into cluutch daily. This is not good.
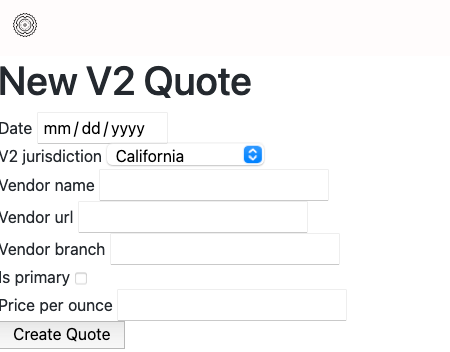
Getting turkers to input results directly into cluutch is gonna be clutch. And the survey layout might be a good solution.
I will direct turkers to a cluutch form pre-filled with all of the information except for price. I will generate and validate unique codes to ensure there are no double entries or double claims. mTurk can accept a CSV with different codes. Now cluutch just needs the ability to generate these codes and prepopulate quote forms accordingly.
The code
Here are the distinct steps required to implement the proposed data collection scheme.
Create new endpoint cluutch.io/crowd-quotes
Update existing quote form to accept 9 different quotes
All the values should be prefilled (eg vendor name), except for price
Prevent all other fields from being edited
Create QuoteRequestedCode
Fields: value (string), is_used (boolean)
Quote belongs to QuoteRequestedCode
Require a QuoteRequestCode that is not used in order to access crowd-quotes
After succesfull submission, QuoteRequestCode is_used should be true
Create QuoteSubmittedCode
Fields: value (string), is_used (boolean)
Quote belongs to QuoteSubmittedCode
After successfull submission, generate new QuoteSubmittedCode and display to user
Create basic admin interface for toggling is_used when HIT confirmed on mTurk.
This is too much. This is too boring. I estimate it would take me half a day of work to complete, test, and deploy all this. Then more time actually validating the results. All to probably wind up with results that are less accurate than what I produce myself now. That said, I know its not sustainable for me to continue recording daily prices myself.
A good compromise is to reduce price data collection to 3 days a week. Monday, Wednesday, and Friday. I hope this reduced load will be easier to manage.
And with the extra time not spent adding extra features for crowdsourcing, I will dive deeper into Augur and creating an oracle during next week’s installment.
That’s it for this week.